Overview of C++23 Features
新年伊始,要说什么选题最合适,那无疑是 C++23 了。
去年只写过 Ranges 和几个小特性的提案,对于其他特性,就全放在此篇一览究竟。
23 是个小版本,主要在于「完善」二字,而非「新增」。因此,值得单独拿出来写篇文章的特性其实并不多,大多特性都是些琐碎小点,三言两语便可讲清。
本篇包含绝大多数 C++23 特性,难度三星就表示只会介绍基本用法,但有些特性的原理也会深入讲讲。
Deducing this(P0847)
Deducing this 是 C++23 中最主要的特性之一。msvc 在去年三月份就已支持该特性,可以在 v19.32 之后的版本使用。
为什么我们需要这个特性?
大家知道,成员函数都有一个隐式对象参数,对于非静态成员函数,这个隐式对象参数就是 this 指针;而对于静态成员函数,这个隐式对象参数被定义为可以匹配任何参数,这仅仅是为了保证重载决议可以正常运行。
Deducing this 所做的事就是提供一种将非静态成员函数的「隐式对象参数」变为「显式对象参数」的方式。为何只针对非静态成员函数呢?因为静态成员函数并没有 this 指针,隐式对象参数并不能和 this 指针划等号,静态函数拥有隐式对象参数只是保证重载决议能够正常运行而已,这个参数没有其他用处。
于是,现在便有两种写法编写非静态成员函数。
struct S_implicit {
void foo() {}
};
struct S_explicit {
void foo(this S_explicit&) {}
};通过 Deducing this,可以将隐式对象参数显式地写出来,语法为 this + type。
该提案最根本的动机是消除成员函数修饰所带来的冗余,举个例子:
// Before
struct S_implicit {
int data_;
int& foo() & { return data_; }
const int& foo() const& { return data_; }
};
// After
struct S_explicit {
int data_;
template <class Self>
auto&& foo(this Self& self) {
return std::forward<Self>(self).data_;
}
};原本你也许得为同一个成员函数编写各种版本的修饰,比如 &, const&, &&, const &&,其逻辑并无太大变化,完全是重复的机械式操作。如今借助 Deducing this,只需编写一个版本即可。
这里使用了模板形式的参数,通常来说,建议是使用 Self 作为显式对象参数的名称,顾名思义的同时又能和其他语言保持一致性。
该特性还有许多使用场景,同时也是一种新的定制点表示方式。比如,借助 Deducing this,可以实现递归 Lambdas。
int main() {
auto gcd = [](this auto self, int a, int b) -> int {
return b == 0 ? a : self(b, a % b);
};
std::cout << gcd(20, 30) << "\n";
}这使得 Lambda 函数再次得到增强。
又比如,借助 Deducing this,可以简化 CRTP。
//// Before
// CRTP
template <class Derived>
struct Base {
void foo() {
auto& self = *static_cast<Derived*>(this);
self.bar();
}
};
struct Derived : Base<Derived> {
void bar() const {
std::cout << "CRTP Derived\n";
}
};
////////////////////////////////////////////
//// After
// Deducing this
struct Base {
template <class Self>
void foo(this Self& self) {
self.bar();
}
};
struct Derived : Base {
void bar() const {
std::cout << "Deducing this Derived\n";
}
};这种新的方式实现 CRTP,可以省去 CR,甚至是 T,要更加自然,更加清晰。
这也是一种新的定制点方式,稍微举个简单点的例子:
// Library
namespace mylib {
struct S {
auto abstract_interface(this auto& self, int param) {
self.concrete_algo1(self.concrete_algo2(param));
}
};
} // namespace mylib
namespace userspace {
struct M : mylib::S {
auto concrete_algo1(int val) {}
auto concrete_algo2(int val) const {
return val * 6;
}
};
} // namespace userspace
int main() {
using userspace::M;
M m;
m.abstract_interface(4);
}这种方式依旧属于静态多态的方式,但代码更加清晰、无侵入,并支持显式 opt-in,是一种值得使用的方式。
定制点并非一个简单的概念,若是看不懂以上例子,跳过便是。(也可参考使用Concepts表示变化「定制点」)
下面再来看其他的使用场景。
Deducing this 还可以用来解决根据 closure 类型完美转发 Lambda 捕获参数的问题。亦即,如果 Lambda 函数的类型为左值,那么捕获的参数就以左值转发;如果为右值,那么就以右值转发。下面是一个例子:
#include <iostream>
#include <type_traits>
#include <utility> // for std::forward_like
auto get_message() {
return 42;
}
struct Scheduler {
auto submit(auto&& m) {
std::cout << std::boolalpha;
std::cout << std::is_lvalue_reference<decltype(m)>::value << "\n";
std::cout << std::is_rvalue_reference<decltype(m)>::value << "\n";
return m;
}
};
int main() {
Scheduler scheduler;
auto callback = [m=get_message(), &scheduler](this auto&& self) -> bool {
return scheduler.submit(std::forward_like<decltype(self)>(m));
};
callback(); // retry(callback)
std::move(callback)(); // try-or-fail(rvalue)
}
// Output:
// true
// false
// false
// true若是没有 Deducing this,那么将无法简单地完成这个操作。另一个用处是可以将 this 以值形式传递,对于小对象来说,可以提高性能。一个例子:
struct S {
int data_;
int foo(); // implicit this pointer
// int foo(this S); // Pass this by value
};
int main() {
S s{42};
return s.foo();
}
// implicit this pointer生成的汇编代码:
// sub rsp, 40 ; 00000028H
// lea rcx, QWORD PTR s$[rsp]
// mov DWORD PTR s$[rsp], 42 ; 0000002aH
// call int S::foo(void) ; S::foo
// add rsp, 40 ; 00000028H
// ret 0
// Pass this by value生成的汇编代码:
// mov ecx, 42 ; 0000002aH
// jmp static int S::foo(this S) ; S::foo对于隐式的 this 指针,生成的汇编代码需要先分配栈空间,保存 this 指针到 rcx 寄存器中,再将 42 赋值到 data_ 中,然后调用 foo(),最后平栈。而以值形式传递 this,则无需那些操作,因为值传递的 this 不会影响 s 变量,中间的步骤都可以被优化掉,也不再需要分配和平栈操作,所以可以直接将 42 保存到寄存器当中,再 jmp 到 foo() 处执行。
Deducing this 是个单独就可写篇四五星难度文章的特性,用处很多,值得深入探索的地方也很多,所以即便是概述这部分也写得比较多。
Monadic std::optional(P0798R8)
P0798 提议为 std::optional 增加三个新的成员:map(), and_then() 和 or_else()。
功能分别为:
map:对optional的值应用一个函数,返回optional中 wrapped 的结果。若是optional中没有值,返回一个空的optional;and_then:组合使用返回optional的函数;or_else:若是有值,返回optional;若是无值,则调用传入的函数,在此可以处理错误。
在 R2 中 map() 被重命名为 transform(),因此实际新增的三个函数为 transform(),and_then() 和 or_else()。
这些函数主要是避免手动检查optional值是否有效,比如:
// Before
if (opt_string) {
std::optional<int> i = stoi(*opt_string);
}
// After
std::optional<int> i = opt_string.and_then(stoi);一个使用的小例子:
// chain a series of functions until there's an error
std::optional<string> opt_string("10");
std::optional<int> i = opt_string
.and_then(std::stoi)
.transform([](auto i) { return i * 2; });错误的情况:
// fails, transform not called, j == nullopt
std::optional<std::string> opt_string_bad("abcd");
std::optional<int> j = opt_string_bad
.and_then(std::stoi)
.transform([](auto i) { return i * 2; });目前 GCC 12,Clang 14,MSVC v19.32 已经支持该特性。
std::expected(P0323)
该特性用于解决错误处理的问题,增加了一个新的头文件 <expected>。
错误处理的逻辑关系为条件关系,若正确,则执行A逻辑;若失败,则执行B逻辑,并需要知道确切的错误信息,才能对症下药。
当前的常用方式是通过错误码或异常,但使用起来还是多有不便。std::expected<T, E> 表示期望,算是 std::variant 和 std::optional 的结合,它要么保留 T(期望的类型),要么保留 E(错误的类型),它的接口又和 std::optional 相似。
一个简单的例子:
enum class Status : uint8_t {
Ok,
connection_error,
no_authority,
format_error,
};
bool connected() {
return true;
}
bool has_authority() {
return false;
}
bool format() {
return false;
}
std::expected<std::string, Status> read_data() {
if (!connected())
return std::unexpected<Status> { Status::connection_error };
if (!has_authority())
return std::unexpected<Status> { Status::no_authority };
if (!format())
return std::unexpected<Status> { Status::format_error };
return {"my expected type"};
}
int main() {
auto result = read_data();
if (result) {
std::cout << result.value() << "\n";
} else {
std::cout << "error code: " << (int)result.error() << "\n";
}
}这种方式无疑会简化错误处理的操作。
该特性目前在 GCC 12,Clang 16(还未发布),MSVC v19.33 已经实现。
Multidimensional Arrays(P2128)
这个特性用于访问多维数组,之前 C++ operator[] 只支持访问单个下标,无法访问多维数组。
因此要访问多维数组,以前的方式是:
- 重载
operator(),于是能够以m(1, 2)来访问第 1 行第 2 个元素。但这种方式容易和函数调用产生混淆; - 重载
operator[],并以std::initializer_list作为参数,然后便能以m[{1, 2}]来访问元素。但这种方式看着别扭; - 链式链接
operator[],然后就能够以m[1][2]来访问元素。同样,看着别扭至极; - 定义一个
at()成员,然后通过at(1, 2)访问元素。同样不方便。
感谢该提案,在 C++23,我们终于可以通过 m[1, 2] 这种方式来访问多维数组。
一个例子:
template <class T, size_t R, size_t C>
struct matrix {
T& operator[](const size_t r, const size_t c) noexcept {
return data_[r * C + c];
}
const T& operator[](const size_t r, const size_t c) const noexcept {
return data_[r * C + c];
}
private:
std::array<T, R * C> data_;
};
int main() {
matrix<int, 2, 2> m;
m[0, 0] = 0;
m[0, 1] = 1;
m[1, 0] = 2;
m[1, 1] = 3;
for (auto i = 0; i < 2; ++i) {
for (auto j = 0; j < 2; ++j) {
std::cout << m[i, j] << ' ';
}
std::cout << std::endl;
}
}该特性目前在 GCC 12 和 Clang 15 以上版本已经支持。
if consteval(P1938)
该特性是关于 immediate function 的,即 consteval function。
解决的问题其实很简单,在 C++20,consteval function 可以调用 constexpr function,而反过来却不行。
consteval auto bar(int m) {
return m * 6;
}
constexpr auto foo(int m) {
return bar(m);
}
int main() {
[[maybe_unused]] auto res = foo(42);
}以上代码无法编译通过,因为 constexpr functiong 不是强保证执行于编译期,在其中自然无法调用 consteval function。
但是,即便加上 if std::is_constant_evaluated() 也无法编译成功。
constexpr auto foo(int m) {
if (std::is_constant_evaluated()) {
return bar(m);
}
return 42;
}这就存在问题了,P1938 通过 if consteval 修复了这个问题。C++23 可以这样写:
constexpr auto foo(int m) {
if consteval {
return bar(m);
}
return 42;
}该特性目前在 GCC 12 和 Clang 14 以上版本已经实现。
Formatted Output(P2093)
该提案就是 std::print(),之前已经说过,这里再简单地说下。
标准 cout 的设计非常糟糕,具体表现在:
- 可用性差,基本没有格式化能力;
- 会多次调用格式化I/0函数;
- 默认会同步标准C,性能低;
- 内容由参数交替组成,在多线程环境,内容会错乱显示;
- 二进制占用空间大;
- ……
随着 Formatting Library 加入 C++20,已在fmt库中使用多年的 fmt::print() 加入标准也是顺理成章。
格式化输出的目标是要满足:可用性、Unicode编码支持、良好的性能,与较小的二进制占用空间。为了不影响现有代码,该特性专门加了一个新的头文件 <print>,包含两个主要函数:
#include <print>
int main() {
const char* world = "world";
std::print("Hello {}", world); // doesn't print a newline
std::println("Hello {}", world); // print a newline
}这对 cout 来说绝对是暴击,std::print 的易用性和性能简直完爆它。
其语法就是 Formatting Library 的格式化语法,可参考 Using C++20 Formatting Library。
性能对比:
----------------------------------------------------------
Benchmark Time CPU Iterations
----------------------------------------------------------
printf 87.0 ns 86.9 ns 7834009
ostream 255 ns 255 ns 2746434
print 78.4 ns 78.3 ns 9095989
print_cout 89.4 ns 89.4 ns 7702973
print_cout_sync 91.5 ns 91.4 ns 7903889结果显示,printf 与 print 几乎要比 cout 快三倍,print 默认会打印到 stdout。当打印到 cout 并同步标准 C 的流时(print_cout_sync),print 大概要快 14%;当不同步标准 C 的流时(print_cout),依旧要快不少。
遗憾的是,该特性目前没有编译器支持。
Formatting Ranges(P2286)
同样属于 Formatting 大家族,该提案使得我们能够格式化输出 Ranges。
也就是说,我们能够写出这样的代码:
import std;
auto main() -> int {
std::vector vec { 1, 2, 3 };
std::print("{}\n", vec); // Output: [1, 2, 3]
}这意味着再也不用迭代来输出 Ranges 了。
这是非常有必要的,考虑一个简单的需求:文本分割。
Python 的实现:
print("how you doing".split(" "))
# Output:
# ['how', 'you', 'doing']Java的实现:
import java.util.Arrays;
class Main {
public static void main(String args[]) {
System.out.println("how you doing".split(" "));
System.out.println(Arrays.toString("how you doing".split(" ")));
}
}
// Output:
// [Ljava.lang.String;@2b2fa4f7
// [how, you, doing]Rust 的实现:
use itertools::Itertools;
fn main() {
println!("{:?}", "How you doing".split(' '));
println!("[{}]", "How you doing".split(' ').format(", "));
println!("{:?}", "How you doing".split(' ').collect::<Vec<_>>());
}
// Output:
// Split(SplitInternal { start: 0, end: 13, matcher: CharSearcher { haystack: "How you doing", finger: 0, finger_back: 13, needle: ' ', utf8_size: 1, utf8_encoded: [32, 0, 0, 0] }, allow_trailing_empty: true, finished: false })
// [How, you, doing]
// ["How", "you", "doing"]JS 的实现:
console.log('How you doing'.split(' '))
// Output:
// ["How", "you", "doing"]Go 的实现:
package main
import "fmt"
import "strings"
func main() {
fmt.Println(strings.Split("How you doing", " "));
}
// Output:
// [How you doing]Kotlin 的实现:
fun main() {
println("How you doing".split(" "));
}
// Output:
// [How, you, doing]C++ 的实现:
int main() {
std::string_view contents {"How you doing"};
auto words = contents
| std::views::split(' ')
| std::views::transform([](auto&& str) {
return std::string_view(&*str.begin(), std::ranges::distance(str));
});
std::cout << "[";
char const* delim = "";
for (auto word : words) {
std::cout << delim;
std::cout << std::quoted(word);
delim = ", ";
}
std::cout << "]\n";
}
// Output:
// ["How", "you", "doing"]借助 fmt,可以简化代码:
int main() {
std::string_view contents {"How you doing"};
auto words = contents
| std::views::split(' ')
| std::views::transform([](auto&& str) {
return std::string_view(&*str.begin(), std::ranges::distance(str));
});
fmt::print("{}\n", words);
fmt::print("<<{}>>", fmt::join(words, "--"));
}
// Output:
// ["How", "you", "doing"]
// <<How--you--doing>>因为 views::split() 返回的是一个 subrange,因此需要将其转变成 string_view,否则,输出将为:
int main() {
std::string_view contents {"How you doing"};
auto words = contents | std::views::split(' ');
fmt::print("{}\n", words);
fmt::print("<<{}>>", fmt::join(words, "--"));
}
// Output:
// [[H, o, w], [y, o, u], [d, o, i, n, g]]
// <<['H', 'o', 'w']--['y', 'o', 'u']--['d', 'o', 'i', 'n', 'g']>>总之,这个特性将极大简化 Ranges 的输出,是比较有用的特性之一。
该特性目前没有编译器支持。
import std(P2465)
C++20 模块很难用的一个原因就是标准模块没有提供,因此这个特性的加入是自然趋势。
现在,可以写出这样的代码:
import std;
int main() {
std::print("Hello standard library modules!\n");
}性能对比:
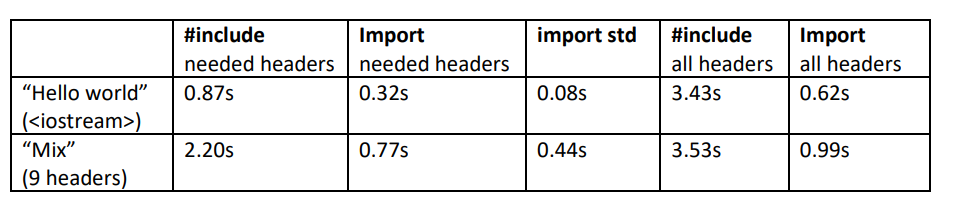
如何你是混合 C 和 C++,那可以使用 std.compat module,所有的C函数和标准库函数都会包含进来。
目前基本没有编译器支持此特性。
out_ptr(P1132r8)
23 新增了两个对于指针的抽象类型,std::out_ptr_t 和 std::inout_ptr_t,两个新的函数std::out_ptr()和std::inout_ptr()分别返回这两个类型。
主要是在和 C API 交互时使用的,一个例子对比一下:
// Before
int old_c_api(int**);
int main() {
auto up = std::make_unique<int>(5);
int* up_raw = up.release();
if (int ec = foreign_resetter(&up)) {
return ec;
}
up.reset(up_raw);
}
////////////////////////////////
// After
int old_c_api(int**);
int main() {
auto up = std::make_unique<int>(5);
if (int ec = foreign_resetter(std::inout_ptr(up))) {
return ec;
}
// *up is still valid
}该特性目前在 MSVC v19.30 支持。
auto(x) decay copy(P0849)
该提案为 auto 又增加了两个新语法:auto(x) 和 auto{x}。两个作用一样,只是写法不同,都是为 x 创建一份拷贝。
为什么需要这么个东西?
看一个例子:
void bar(const auto&);
void foo(const auto& param) {
auto copy = param;
bar(copy);
}foo() 中调用 bar(),希望传递一份 param 的拷贝,则我们需要单独多声明一个临时变量。或是这样:
void foo(const auto& param) {
bar(std::decay_t<decltype(param)>{param});
}这种方式需要手动去除多余的修饰,只留下 T,要更加麻烦。
auto(x) 就是内建的 decay copy,现在可以直接这样写:
void foo(const auto& param) {
bar(auto{param});
}大家可能还没意识到其必要性,来看提案当中更加复杂一点的例子。
void pop_front_alike(auto& container) {
std::erase(container, container.front());
}
int main() {
std::vector fruits{ "apple", "apple", "cherry", "grape",
"apple", "papaya", "plum", "papaya", "cherry", "apple"};
pop_front_alike(fruits);
fmt::print("{}\n", fruits);
}
// Output:
// ["cherry", "grape", "apple", "papaya", "plum", "papaya", "apple"]请注意该程序的输出,是否如你所想的一样。若没有发现问题,请让我再提醒一下:pop_front_alike() 要移除容器中所有跟第 1 个元素相同的元素。
因此,理想的结果应该为:
["cherry", "grape", "papaya", "plum", "papaya", "cherry"]是哪里出了问题呢?让我们来看看 GCC std::erase() 的实现:
template<typename _ForwardIterator, typename _Predicate>
_ForwardIterator
__remove_if(_ForwardIterator __first, _ForwardIterator __last,
_Predicate __pred)
{
__first = std::__find_if(__first, __last, __pred);
if (__first == __last)
return __first;
_ForwardIterator __result = __first;
++__first;
for (; __first != __last; ++__first)
if (!__pred(__first)) {
*__result = _GLIBCXX_MOVE(*__first);
++__result;
}
return __result;
}
template<typename _Tp, typename _Alloc, typename _Up>
inline typename vector<_Tp, _Alloc>::size_type
erase(vector<_Tp, _Alloc>& __cont, const _Up& __value)
{
const auto __osz = __cont.size();
__cont.erase(std::remove(__cont.begin(), __cont.end(), __value),
__cont.end());
return __osz - __cont.size();
}std::remove() 最终调用的是 remove_if(),因此关键就在这个算法里面。这个算法每次会比较当前元素和欲移除元素,若不相等,则用当前元素覆盖当前 __result 迭代器的值,然后__result 向后移一位。重复这个操作,最后全部有效元素就都跑到 __result 迭代器的前面去了。
问题出在哪里呢?欲移除元素始终指向首个元素,而它会随着元素覆盖操作被改变,因为它的类型为 const T&。
此时,必须重新 copy 一份值,才能得到正确的结果。故将代码小作更改,就能得到正确的结果。
void pop_front_alike(auto& container) {
auto copy = container.front();
std::erase(container, copy);
}然而这种方式是非常反直觉的,一般来说这两种写法的效果应该是等价的。
我们将 copy 定义为一个单独的函数,表达效果则要好一点。
auto copy(const auto& value) {
return value;
}
void pop_front_alike(auto& container) {
std::erase(container, copy(container.front()));
}而 auto{x} 和 auto(x),就相当于这个 copy() 函数,只不过它是内建到语言里面的而已。
Narrowing contextual conversions to bool
这个提案允许在 static_assert和 if constexpr 中从整形转换为布尔类型。
以下表格就可以表示所有内容。
| Before | After |
|---|---|
if constexpr(bool(flags & Flags::Exec)) |
if constexpr(flags & Flags::Exec) |
if constexpr(flags & Flags::Exec != 0) |
if constexpr(flags & Flags::Exec) |
static_assert(N % 4 != 0); |
static_assert(N % 4); |
static_assert(bool(N)); |
static_assert(N); |
对于严格的 C++ 编译器来说,以前在这种情境下 int 无法向下转换为 bool,需要手动强制转换,C++23 这一情况得到了改善。
目前在 GCC 9 和 Clang 13 以上版本支持该特性。
forward_like(P2445)
这个在 Deducing this 那节已经使用过了,是同一个作者。
使用情境让我们回顾一下这个例子:
auto callback = [m = get_message(), &scheduler](this auto&& self) -> bool {
return scheduler.submit(std::forward_like<decltype(self)>(m));
};
callback(); // retry(callback)
std::move(callback)(); // try-or-fail(rvalue)std::forward_like 加入到了 <utility> 中,就是根据模板参数的值类别来转发参数。
如果 closure type 为左值,那么 m 将转发为左值;如果为右值,将转发为右值。
听说Clang 16和MSVC v19.34支持该特性,但都尚未发布。
#elifdef and #elifndef(P2334)
这两个预处理指令来自WG14(C的工作组),加入到了C23。C++为了兼容C,也将它们加入到了C++23。
也是一个完善工作。
#ifdef 和 #ifndef 分别是 #if defined() 和 #if !defined() 的简写,而 #elif defined() 和 #elif !defined() 却并没有与之对应的简写指令。因此,C23使用#elifdef 和 #elifndef 来补充这一遗漏。
总之,是两个非常简单的小特性。目前已在GCC 12和Clang 13得到支持。
#warning(P2437)
#warning 是主流编译器都会支持的一个特性,最终倒逼C23和C++23也加入了进来。
这个小特性可以用来产生警告信息,与#error不同,它并不会停止翻译。用法很简单:
#ifndef FOO
#warning "FOO defined, performance might be limited"
#endif目前MSVC不支持该特性,其他主流编译器都支持。
constexpr std::unique_ptr(P2273R3)
std::unique_ptr 也支持编译期计算了,一个小例子:
constexpr auto fun() {
auto p = std::make_unique<int>(4);
return *p;
}
int main() {
constexpr auto i = fun();
static_assert(4 == i);
}目前GCC 12和MSVC v19.33支持该特性。
Improving string and string_view(P1679R3, P2166R1, P1989R2, P1072R10, P2251R1)
string 和 string_view 也获得了一些增强,这里简单地说下。
P1679 为二者增加了一个 contain() 函数,小例子:
std::string str("dummy text");
if (str.contains("dummy")) {
// do something
}目前GCC 11,Clang 12,MSVC v19.30支持该特性。
P2166 使得它们从 nullptr 构建不再产生UB,而是直接编译失败。
std::string s { nullptr }; // error!
std::string_view sv { nullptr }; // error!目前GCC 12,Clang 13,MSVC v19.30支持该特性。
P1989是针对 std::string_view 的,一个小例子搞定:
int main() {
std::vector v { 'a', 'b', 'c' };
// Before
std::string_view sv(v.begin(), v.end());
// After
std::string_view sv23 { v };
}以前无法直接从Ranges构建 std::string_view,而现在支持这种方式。
该特性在GCC 11,Clang 14,MSVC v19.30已经支持。
P1072为 string 新增了一个成员函数:
template< class Operation >
constexpr void resize_and_overwrite( size_type count, Operation op );可以通过提案中的一个示例来理解:
int main() {
std::string s { "Food: " };
s.resize_and_overwrite(10, [](char* buf, int n) {
return std::find(buf, buf + n, ':') - buf;
});
std::cout << std::quoted(s) << '\n'; // "Food"
}主要是两个操作:改变大小和覆盖内容。第 1 个参数是新的大小,第 2 个参数是一个 op,用于设置新的内容。
然后的逻辑是:
- 如果
maxsize <= s.size(),删除最后的size() - maxsize个元素; - 如果
maxsize > s.size(),追加maxsize - size()个默认元素; - 调用
erase(begin() + op(data(), maxsize), end())。
这里再给出一个例子,可以使用上面的逻辑来走一遍,以更清晰地理解该函数。
constexpr std::string_view fruits[] {"apple", "banana", "coconut", "date", "elderberry"};
std::string s1 { "Food: " };
s1.resize_and_overwrite(16, [sz = s1.size()](char* buf, std::size_t buf_size) {
const auto to_copy = std::min(buf_size - sz, fruits[1].size()); // 6
std::memcpy(buf + sz, fruits[1].data(), to_copy); // append "banana" to s1.
return sz + to_copy; // 6 + 6
});
std::cout << s1; // Food: banana注意一下,maxsize 是最大的可能大小,而 op 返回才是实际大小,因此逻辑的最后才有一个 erase() 操作,用于删除多余的大小。
这个特性在GCC 12,Clang 14,MSVC v19.31已经实现。
接着来看P2251,它更新了 std::span 和 std::string_view 的约束,从C++23开始,它们必须满足 TriviallyCopyable Concept。
主流编译器都支持该特性。
最后来看P0448,其引入了一个新的头文件 <spanstream>。
大家都知道,stringstream 现在被广泛使用,可以将数据存储到 string 或 vector 当中,但这些容器当数据增长时会发生「挪窝」的行为,若是不想产生这个开销呢?
<spanstream> 提供了一种选择,你可以指定固定大小的 buffer,它不会重新分配内存,但要小心数据超出 buffer 大小,此时内存的所有权在程序员这边。
一个小例子:
#define ASSERT_EQUAL(a, b) assert(a == b)
#define ASSERT(a) assert(a)
int main() {
char input[] = "10 20 30";
std::ispanstream is{ std::span<char>{input} };
int i;
is >> i;
ASSERT_EQUAL(10,i);
is >> i;
ASSERT_EQUAL(20,i);
is >> i;
ASSERT_EQUAL(30,i);
is >> i;
ASSERT(!is);
}目前GCC 12和MSVC v19.31已支持该特性。
static operator()(P1169R4)
因为函数对象、Lambdas使用得越来越多,经常作为标准库的定制点使用。这种函数对象只有一个 operator (),如果允许声明为 static,则可以提高性能。
至于原理,大家可以回顾一下 Deducing this 那节的 Pass this by value 提高性能的原理。明白静态函数和非静态函数在重载决议中的区别,大概就能明白这点。
顺便一提,由于 Mutidimensional operator[] 如今已经可以达到和 operator() 一样的效果,它也可以作为一种新的函数语法,你完全可以这样调用 foo[],只是不太直观。因此,P2589 也提议了 static operator[]。
std::unreachable(P0627R6)
当我们知道某个位置是不可能执行到,而编译器不知道时,使用 std::unreachalbe 可以告诉编译器,从而避免没必要的运行期检查。
一个简单的例子:
void foo(int a) {
switch (a) {
case 1:
// do something
break;
case 2:
// do something
break;
default:
std::unreachable();
}
}
bool is_valid(int a) {
return a == 1 || a == 2;
}
int main() {
int a = 0;
while (!is_valid(a))
std::cin >> a;
foo(a);
}该特性位于 <utility>,在GCC 12,Clang 15和MSVC v19.32已经支持。
std::to_underlying(P1682R3)
同样位于 <utility>,用于枚举到其潜在的类型,相当于以下代码的语法糖:
static_cast<std::underlying_type_t<Enum>>(e);一个简单的例子就能看懂:
void print_day(int a) {
fmt::print("{}\n", a);
}
enum class Day : std::uint8_t {
Monday = 1,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday,
Sunday
};
int main() {
// Before
print_day(static_cast<std::underlying_type_t<Day>>(Day::Monday));
// C++23
print_day(std::to_underlying(Day::Friday));
}的确很简单吧!
该特性目前在GCC 11,Clang 13,MSVC v19.30已经实现。
std::byteswap(P1272R4)
位于 <bit>,顾名思义,是关于位操作的。
同样,一个例子看懂:
template <std::integral T>
void print_hex(T v)
{
for (std::size_t i = 0; i < sizeof(T); ++i, v >>= 8)
{
fmt::print("{:02X} ", static_cast<unsigned>(T(0xFF) & v));
}
std::cout << '\n';
}
int main()
{
unsigned char a = 0xBA;
print_hex(a); // BA
print_hex(std::byteswap(a)); // BA
unsigned short b = 0xBAAD;
print_hex(b); // AD BA
print_hex(std::byteswap(b)); // BA AD
int c = 0xBAADF00D;
print_hex(c); // 0D F0 AD BA
print_hex(std::byteswap(c)); // BA AD F0 0D
long long d = 0xBAADF00DBAADC0FE;
print_hex(d); // FE C0 AD BA 0D F0 AD BA
print_hex(std::byteswap(d)); // BA AD F0 0D BA AD C0 FE
}可以看到,其作用是逆转整型的字节序。当需要在两个不同的系统传输数据,它们使用不同的字节序时(大端小端),这个工具就会很有用。
该特性目前在GCC 12,Clang 14和MSVC v19.31已经支持。
std::stacktrace(P0881R7, P2301R1)
位于 <stacktrace>,可以让我们捕获调用栈的信息,从而知道哪个函数调用了当前函数,哪个调用引发了异常,以更好地定位错误。
一个小例子:
void foo() {
auto trace = std::stacktrace::current();
std::cout << std::to_string(trace) << '\n';
}
int main() {
foo();
}输出如下:
# foo() at /app/example.cpp:5
# at /app/example.cpp:10
# at :0
# at :0
#注意,目前GCC 12.1和MSVC v19.34支持该特性,GCC 编译时要加上 -lstdc++_libbacktrace 参数。
std::stacktrace 是 std::basic_stacktrace 使用默认分配器时的别名,定义为:
using stacktrace = std::basic_stacktrace<std::allocator<std::stacktrace_entry>>;而P2301,则是为其添加了PMR版本的别名,定义为:
namespace pmr {
using stacktrace =
std::basic_stacktrace<std::pmr::polymorphic_allocator<std::stacktrace_entry>>;
}于是使用起来就会方便一些。
// Before
char buffer[1024];
std::pmr::monotonic_buffer_resource pool{
std::data(buffer), std::size(buffer)};
std::basic_stacktrace<
std::pmr::polymorphic_allocator<std::stacktrace_entry>>
trace{&pool};
// After
char buffer[1024];
std::pmr::monotonic_buffer_resource pool{
std::data(buffer), std::size(buffer)};
std::pmr::stacktrace trace{&pool};这个特性到时再单独写篇文章,在此不细论。
Attributes(P1774R8, P2173R1, P2156R1)
Attributes在C++23也有一些改变。
首先,P1774新增了一个 Attribute [[assume]],其实在很多编译器早已存在相应的特性,例如 __assume()(MSVC, ICC),__builtin_assume()(Clang)。GCC没有相关特性,所以它也是最早实现标准 [[assume]] 的,目前就GCC 13支持该特性(等四月发布,该版本对Rangs的支持也很完善)。
现在可以通过宏来玩:
#if defined(__clang__)
#define ASSUME(expr) __builtin_assume(expr)
#elif defined(__GNUC__) && !defined(__ICC)
#define ASSUME(expr) if (expr) {} else { __builtin_unreachable(); }
#elif defined(_MSC_VER) || defined(__ICC)
#define ASSUME(expr) __assume(expr)
#endif论文当中的一个例子:
void limiter(float* data, size_t size) {
ASSUME(size > 0);
ASSUME(size % 32 == 0);
for (size_t i = 0; i < size; ++i) {
ASSUME(std::isfinite(data[i]));
data[i] = std::clamp(data[i], -1.0f, 1.0f);
}
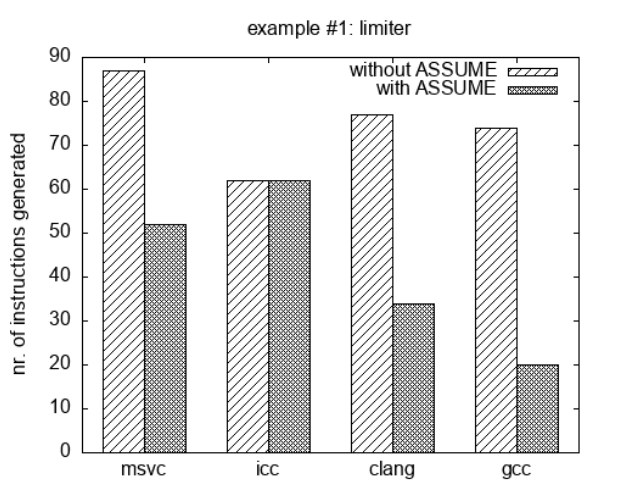
}第一个是假设 size 永不为 0,总是正数;第二个告诉编译器 size 总是 32 的倍数;第三个表明数据不是 NaN 或无限小数。
这些假设不会被评估,也不会被检查,编译器假设其为真,依此优化代码。若是假设为假,可能会产生UB。
使用该特性与否编译产生的指令数对比结果如下图。
其次,P2173使得可以在Lambda表达式上使用Attributes,一个例子:
// Any attribute so specified does not appertain to the function
// call operator or operator template itself, but its type.
auto lam = [][[nodiscard]] ->int { return 42; };
int main()
{
lam();
}
// Output:
// <source>: In function 'int main()':
// <source>:12:8: warning: ignoring return value of '<lambda()>', declared with attribute 'nodiscard' [-Wunused-result]
// 12 | lam();
// | ~~~^~
// <source>:8:12: note: declared here
// 8 | auto lam = [][[nodiscard]] ->int { return 42; };
// | ^注意,Attributes 属于 closure type,而不属于 operator ()。因此,有些 Attributes 不能使用,比如 [[noreturn]],它表明函数的控制流不会返回到调用方,而Lambda函数是会返回的。除此之外,此处还展示了C++的另一个Lambda特性。在C++23之前,最简单的Lambda表达式为 [](){},而到了C++23,则是 []{},可以省略无参时的括号,这得感谢P1102。
早在GCC 9就支持Attributes Lambda,Clang 13如今也支持。
最后来看P2156,它移除了重复Attributes的限制。
简单来说,两种重复Attributes的语法评判不一致。例子:
// Not allow
[[nodiscard, nodiscard]] auto foo() {
return 42;
}
// Allowed
[[nodiscard]][[nodiscard]] auto foo() {
return 42;
}为了保证一致性,去除此限制,使得标准更简单。
什么时候会出现重复Attributes,看论文怎么说:
During this discussion, it was brought up that
the duplication across attribute-specifiers are to support cases where macros are used to conditionally add attributes to an
attribute-specifier-seq, however it is rare for macros to be used to generate attributes within the same attribute-list. Thus,
removing the limitation for that reason is unnecessary.
在基于宏生成的时候可能会出现重复Attributes,因此允许第二种方式;宏生成很少使用第一种形式,于是标准限制了这种情况。但这却并没有让标准变得更简单。因此,最终移除了该限制。
目前使用GCC 11,Clang 13以上两种形式的结果将保持一致。
Lambdas(P1102R2, P2036R3, P2173R1)
Lambdas表达式在C++23也再次迎来了一些新特性。
像是支持Attributes,可以省略 (),这在Attributes这一节已经介绍过,不再赘述。
另一个新特性是P2036提的,接下来主要说说这个。
这个特性改变了 trailing return types 的Name Lookup规则,为什么?让我们来看一个例子。
double j = 42.0;
// ...
auto counter = [j = 0]() mutable -> decltype(j) {
return j++;
};counter 最终的类型是什么?是 int 吗?还是 double?其实是 double。
无论捕获列表当中存在什么值,trailing return type 的 Name Lookup 都不会查找到它。
这意味着单独这样写将会编译出错:
auto counter = [j=0]() mutable -> decltype(j) {
return j++;
};
// Output:
// <source>:6:44: error: use of undeclared identifier 'j'
// auto counter = [j=0]() mutable -> decltype(j) {
// ^对于trailing return type来说,根本就看不见捕获列表中的 j。
以下例子能够更清晰地展示这个错误:
template <typename T> int bar(int&, T&&); // #1
template <typename T> void bar(int const&, T&&); // #2
int i;
auto f = [=](auto&& x) -> decltype(bar(i, x)) {
return bar(i, x);
}
f(42); // error在C++23,Trailing return types 的 Name Lookup 规则变为:在外部查找之前,先查找捕获列表,从而解决这个问题。
目前没有任何编译器支持该特性。
Literal suffixes for (signed) size_t(P0330R8)
这个特性为 std::size_t 增加了后缀 uz,为 signed std::size_t 加了后缀 z。
有什么用呢?看个例子:
#include <vector>
int main() {
std::vector<int> v{0, 1, 2, 3};
for (auto i = 0u, s = v.size(); i < s; ++i) {
/* use both i and v[i] */
}
}这代码在32 bit平台编译能够通过,而放到64 bit平台编译,则会出现错误:
<source>(5): error C3538: in a declarator-list 'auto' must always deduce to the same type
<source>(5): note: could be 'unsigned int'
<source>(5): note: or 'unsigned __int64'在32 bit平台上,i 被推导为 unsigned int,v.size() 返回的类型为 size_t。而 size_t 在32 bit上为 unsigned int,而在64 bit上为 unsigned long long。(in MSVC)
因此,同样的代码,从32 bit切换到64 bit时就会出现错误。
而通过新增的后缀,则可以保证这个代码在任何平台上都能有相同的结果。
#include <vector>
int main() {
std::vector<int> v{0, 1, 2, 3};
for (auto i = 0uz, s = v.size(); i < s; ++i) {
/* use both i and v[i] */
}
}如此一来就解决了这个问题。
目前GCC 11和Clang 13支持该特性。
std::mdspan(P0009r18)
std::mdspan 是 std::span 的多维版本,因此它是一个多维 Views。
看一个例子,简单了解其用法。
int main()
{
std::vector v = {1,2,3,4,5,6,7,8,9,10,11,12};
// View data as contiguous memory representing 2 rows of 6 ints each
auto ms2 = std::experimental::mdspan(v.data(), 2, 6);
// View the same data as a 3D array 2 x 3 x 2
auto ms3 = std::experimental::mdspan(v.data(), 2, 3, 2);
// write data using 2D view
for(size_t i=0; i != ms2.extent(0); i++)
for(size_t j=0; j != ms2.extent(1); j++)
ms2[i, j] = i*1000 + j;
// read back using 3D view
for(size_t i=0; i != ms3.extent(0); i++)
{
fmt::print("slice @ i = {}\n", i);
for(size_t j=0; j != ms3.extent(1); j++)
{
for(size_t k=0; k != ms3.extent(2); k++)
fmt::print("{} ", ms3[i, j, k]);
fmt::print("\n");
}
}
}目前没有编译器支持该特性,使用的是 mdspan 实现的版本,所以在 experimental 下面。
ms2 是将数据以二维形式访问,ms3 则以三维访问,Views 可以改变原有数据,因此最终遍历的结果为:
1slice @ i = 0
20 1
32 3
44 5
5slice @ i = 1
61000 1001
71002 1003
81004 1005这个特性值得剖析下其设计,这里不再深究,后面单独出一篇文章。
flat_map, flat_set(P0429R9, P1222R4)
C++23 多了 flat version的 map 和 set:
flat_mapflat_setflat_multimapflat_multiset
过去的容器,有的使用二叉树,有的使用哈希表,而flat版本的使用的连续序列的容器,更像是容器的适配器。
无非就是时间或空间复杂度的均衡,目前没有具体测试,也没有编译器支持,暂不深究。